How Can We Help?
Search for answers or browse our knowledge base.
2.1 Release Notes
Release Topics:
- OneDrive Source Configuration
- Memory Optimization Enhancements
- Classification Enhancements
- Manual Export Improvements
- Local Dynamic Workers
- Dynamic Forms
- OCR Supports Multiple Languages
- Manual Export by Query Audit Messages
New Features
Below are the highlights of the new features, tech debts and limitations for the 2.1 release:
1. OneDrive Source Configuration: enables the platform to connect to OneDrive’s cloud storage and perform the following functions for both Windows and Linux OS:
- Index
- Classify
- OCR
- STATS functionality provides information about the existence of files for each subsequent scan
- Deleting files from OneDrive
Note: Due to scalability limits with our current connector architecture, the OneDrive Connector will be released as a beta connector.
To learn more about configuring OneDrive as an administrative user, click here.
2. Memory Optimization Enhancements: enabling memory paging on the same drive where the Aparavi application is installed will result in optimization of engine memory consumption and memory fragmentation. This will ensure that if the engine runs out of free memory the OS will use the disk drive preventing the engine from crashing. After enablement, part of the memory will be stored on the drive within a file named C:/pagefile.sys to be used as expandable memory for the platform.
Please Note: when memory paging is enabled, allocating free disk space will require that the paging file is set at a minimum of 64 GB. However, the recommended size is 128 GB.
To learn how to turn on memory paging for Windows OS, click here.
To learn how to turn on memory paging for Linux OS, click here.
3. Classification Enhancements: System will display the rules for each classification. This will increase visibility to clarify the requirements for each classification applied.
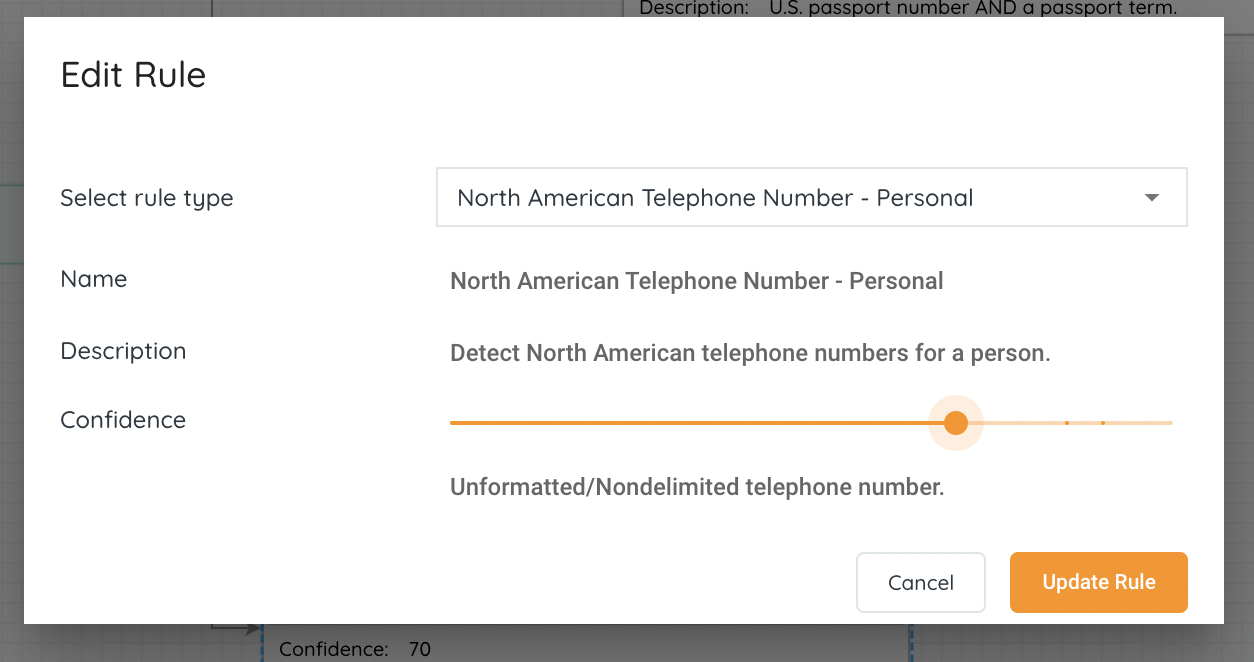
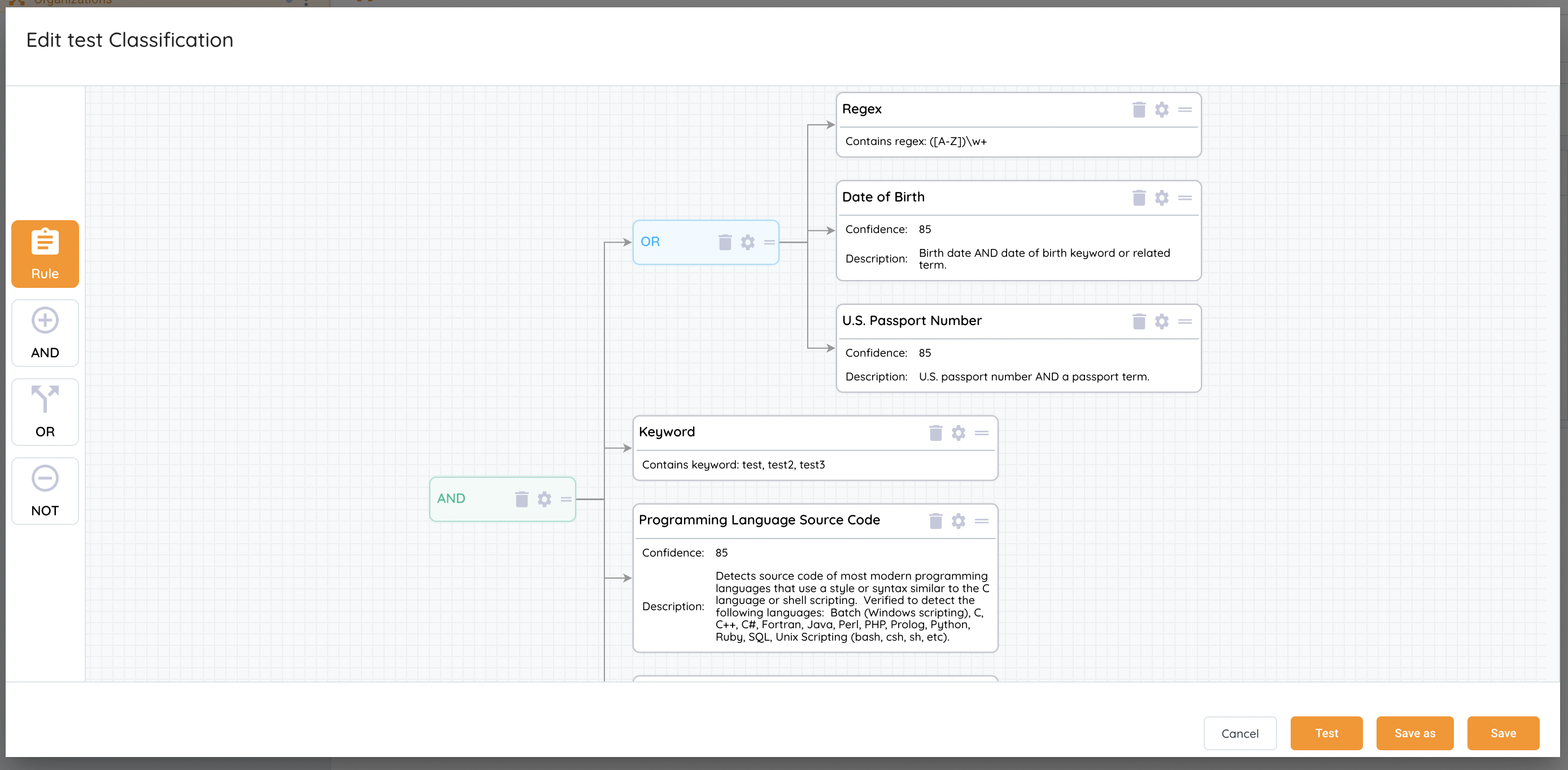
4. Manual Export Improvements: the platform now offers two options when exporting files following a file search.
- Manual Export by Select: after a file search is performed, the system allows for exporting 25k files at once. This type of export occurs when the checkboxes to the left of the file names have been selected, followed by clicking the export button.
To learn how to manually export selected files, click here.
- Manual Export by Query: after a file search is performed, the system allows for exporting an unlimited amount of files at once. This type of export occurs after clicking the export data button, without selecting any files.
To learn how to manually export files by query, click here.
5. Dynamic Forms: the system now permits the parameters & properties to connect based on inputs in the backend. This allows for configuring connectors to transpire dynamically.
6. OCR Supports Multiple Languages: previously in version 2.0, the system did not have the ability to utilize the OCR feature in any language except for English. In version 2.1 the platform now supports the following languages:
- French
- English
- German
- Italian
- Spanish
7. Manual Export by Query Audit Messages: the system will provide auditing messages when files are exported by query. The information will track details such as the time the export was performed and who performed it.
Additional Improvements
File Management Options
- Delete up to 25K files at once following a file search
- Delete up to 25K files at once by selecting a folder from the navigation tree
- Export up to 25K files at once using Export by Select
- Export an unlimited number of files at once using Export by Query
Dashboard
- The dashboard will omit negative values
- Widgets will now include Permissions & Data Owners
Search Improvements
- Search by BUILDER supports file searching using classifications
Performance Improvements
- Overflow files created by the engine will now be eliminated, improving processing speed and storage space
- The system utilizes significantly less memory when parsing large files
UI
- All nodes configured will properly display their online status
- System will no longer stall when the Configuration subtab is selected
Tech Debts
- Upgrade Tika
- Upgrade Tesseract
- Upgrade TLS version from 1.0 to 1.3