How Can We Help?
Search for answers or browse our knowledge base.
2.2 Release Notes
The Release Notes will help stakeholders understand what’s new in the 2.2 Release.
Highlights on the features and improvements will be provided.
- The main theme of this release is “Classifications” and to get insights on what’s new on Classifications, let’s dive a bit.
Sales Enablers
Perform Re-classify
- A key feature which helps customers to perform re-classify on already scanned / indexed data. When we add, edit or remove classifications, the re- classify will be triggered on the already indexed data.
- As soon as the classifications are added or removed, the re-classify pipeline will be executed.
- File Search – will have the search filters for classifications updated to what new classifications were added/removed as shown below.
- The dashboard will reflect the changes of the added, edited or removed classifications and hence this enhances user experience and avoids confusing the user anymore.
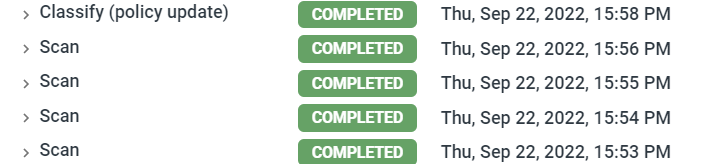
- The logs does show the classify being performed and this will enhance user experience too.
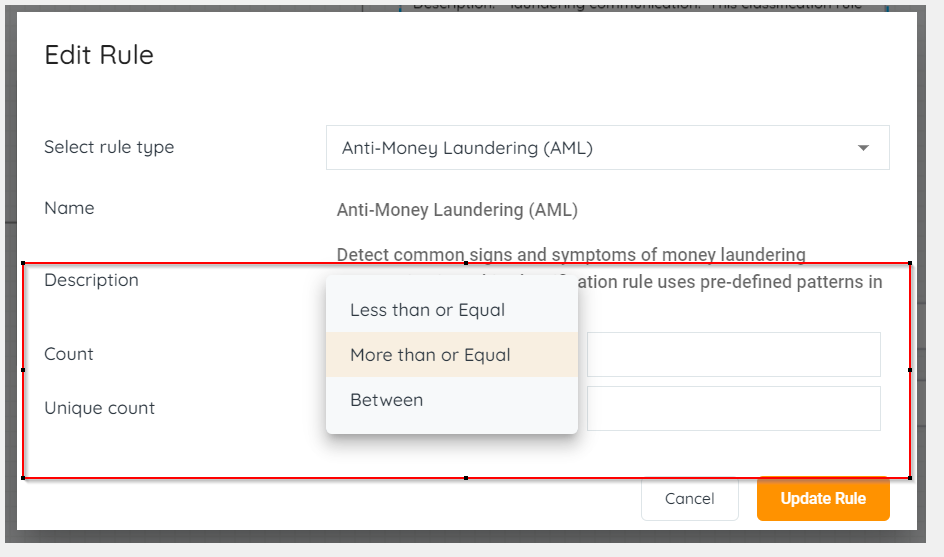
Possibility to customize pre-defined classifications
With this feature, the platform has capabilities to customize pre-defined classifications by changing the following parameters for each rule within a classification policy
- Count – The number of non-unique instances of the Classification Rule that must be found in order for the ClassificationRule element to match
- Unique Count – The number of unique instances of the Classification Rule that must be found in order for the ClassificationRule element to match.
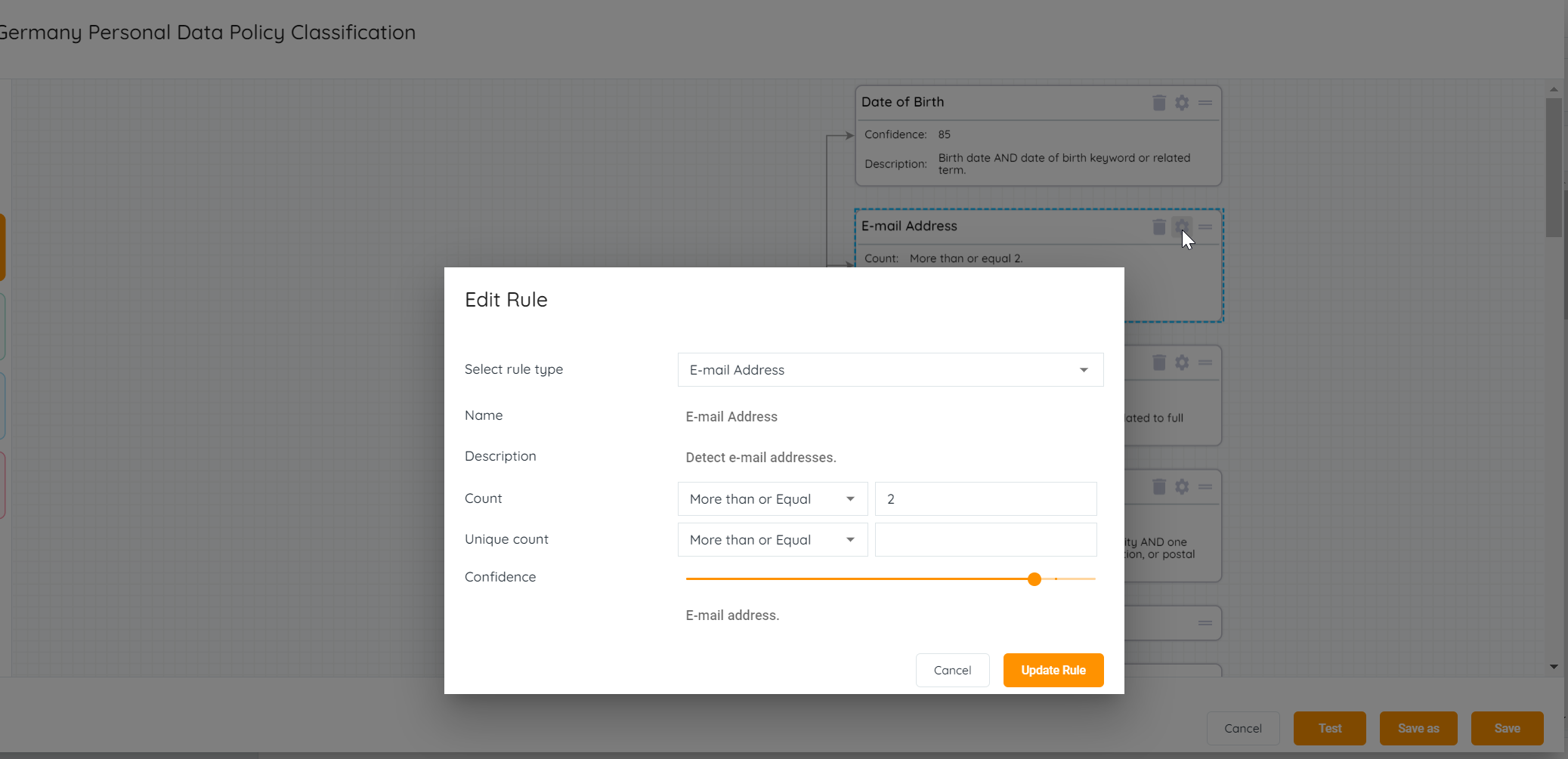
- Edit Window : The most common example with the German Personal data Policy has the email address rule within with a default of 10 , which now is possible to change and adjust to the needs of the customer or our internal customer facing teams.
- In the View window , these changes are reflected too and which will help user understand the changes saved.
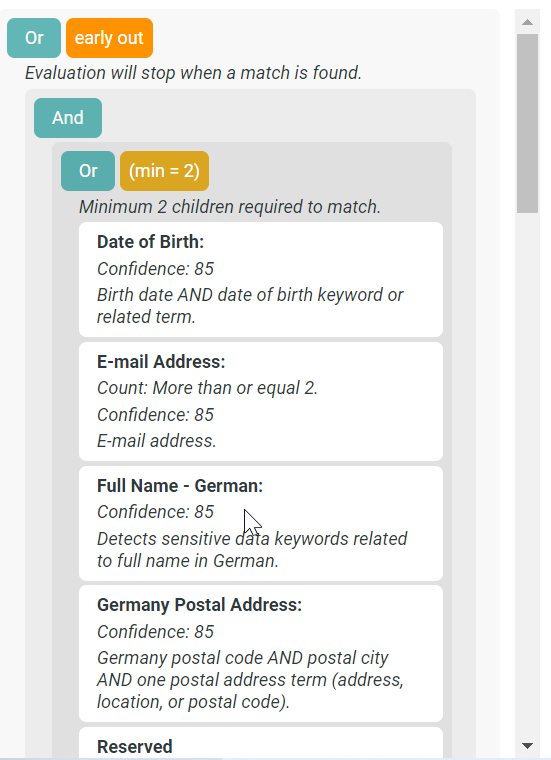
- Diagram View :
Diagram View

Core Scan Lite
- With this feature , we have the possibility to run a Core Scan with or without Content Signature (this is enabled by default) but could be disabled and give them results as fast as possible. This helps them first assess the data they have and then go to next steps on what kind of data should be indexed or classified.
- Hence now the UI has additional toggle “Content Signature” which needs to be enabled for identifying duplicates.
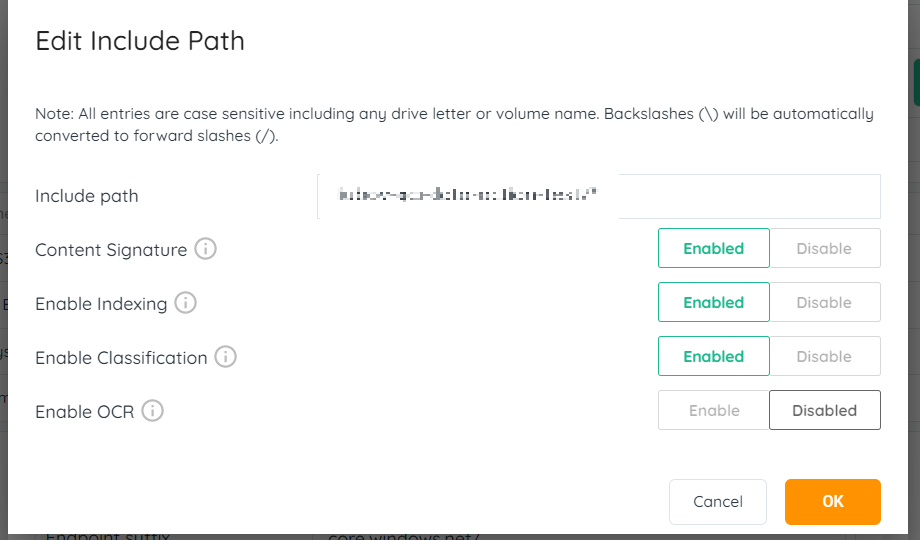
- This toggle enables users to split the file signature to another step and perform faster Core Scan.
- These toggles shown above in the picture are interdependent, they can be turned on in the sequence as you see in the picture above.
Zombie Folders
- Zombie Folders are those folders which do not have children (files/folders). These folders are there by marked as deleted and will be not visible in the UI. But in some cases, the folders are still available and this is because our platform has still copies of these files irrespective of whether the files are in the primary source or secondary and those files must still remain accessible to the user wherever they exist. Our platform should be capable of helping user find all relevant files , hence folders who have its data copied to targets are still available inside Aparavi Platform and this is no special use case.
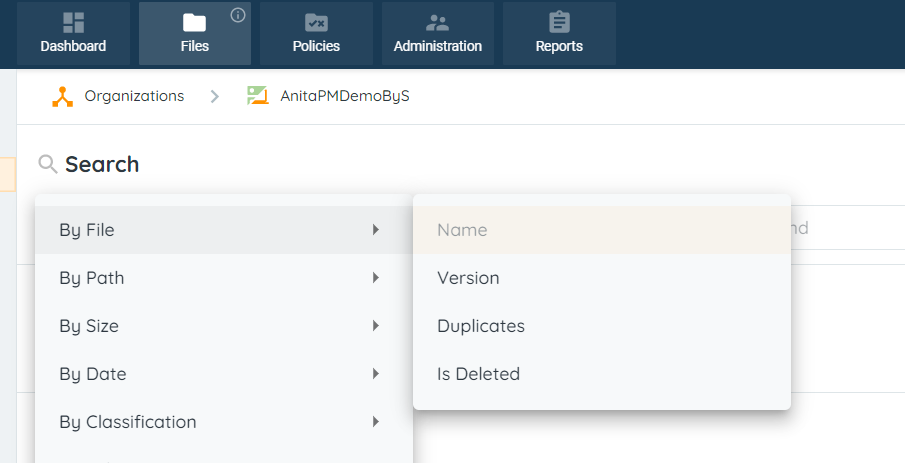
- We have removed the filters for showing deleted files or folders from the UI. We always only show active data. To see deleted data , we can use the new search filters we have as shown here :
Enhanced Scan Scheduling
This feature gives the possibility to schedule scans or automate them. We have various possibilities to perform automated scans with various frequencies.
- Daily (Every week day at a certain time) can be scheduled
- Weekly (Recurring cycle , day and time) can be scheduled.
- Monthly (Recurring cycle, date and time) can be scheduled.
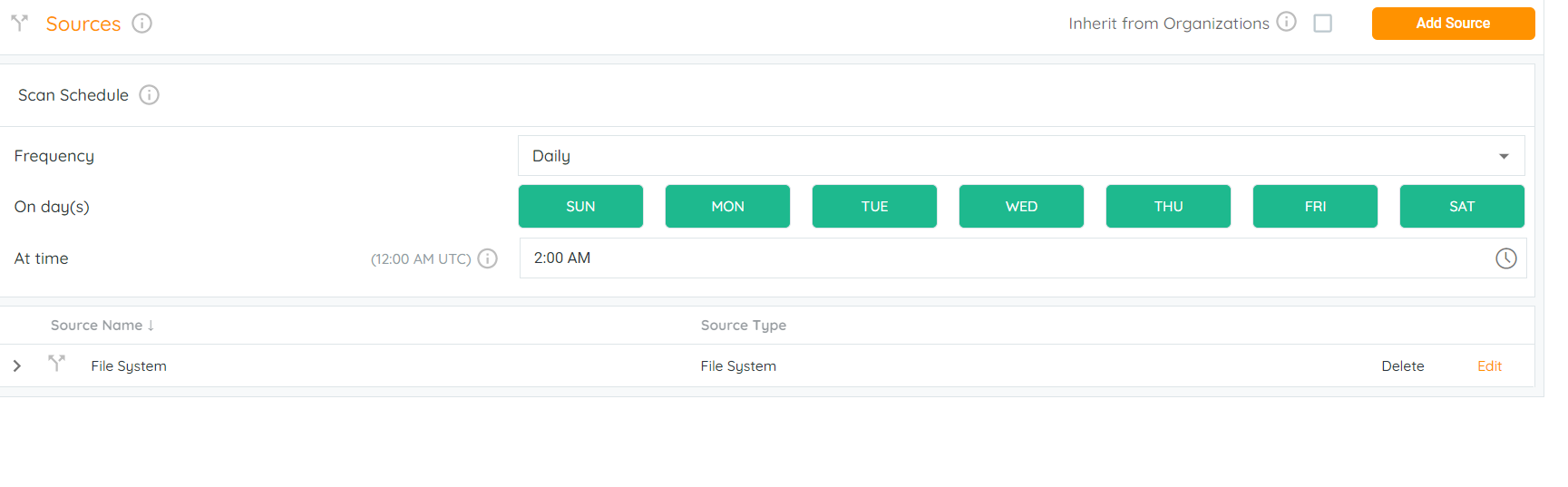
Note : Once the scan has been scheduled of any frequency mentioned above , the scan scheduler will be effective from next 24 hours.
Linux – creation date, modified date appear in dashboards
This feature is mainly focused for Linux distributives that our dashboard resolves issues with Creation date widget. Until 2.1 release, we were not populating the widget of Creation date as we never received this info from the internal function we used. Now we are using “statx” function and it helps us provide this metadata and which enhances our platform value.
Support Cloud Migration
Support manual data export to s3 / s3-compat
This feature is allowing users to export their data to AWS S3 and S3 Compats in native format. This will be a very good feature to enhance Cloud Migration and definitely adding business value to this use case.
Support manual data export to SMB
This feature is allowing users to export their data to SMB in native format. This will be a very good feature to enhance Cloud Migration and definitely adding business value to this use case.
Connectors
AWS S3 as a source
This is a new connector possibility to connect data sources related to AWS S3. The parameters to connect to AWS S3 are available and as usual we have to validate once credentials are added.
With this new connector to AWS S3 we can perform Core scan, content signature, index and classify similar to any other existing services.
S3 Compat as a Source
This is a new connector possibility to connect data sources related to S3 Compat. The parameters to connect to S3 Compat are available and as usual we have to validate once credentials are added.
With this new connector to S3 Compat we can perform Core scan, content signature, index and classify similar to any other existing services.
Azure Blob as a Source
This is a new connector possibility to connect data sources related to Azure Blob The parameters to connect to Aure Blob are available and as usual we have to validate once credentials are added.
With this new connector to Azure Blob we can perform Core scan, content signature, index and classify similar to any other existing services.
Performance
Improved Memory Resource Usage
- Memory optimization by removal of case sensitive index.
- Memory optimization by reducing word storage in memory during runtime