How Can We Help?
Search for answers or browse our knowledge base.
Tagging
Purpose
The purpose of this article is to take a deeper look into the use of Tags and some of the use cases and reasons why you would want to use Tags. Tagging is something that is not new in the IT world, possibly leveraged in other aspects of your job, for example VMware Tags in vSphere. The ability to create custom labels for your Virtual Machines allows for easier organization and searching options. The same is true with tagging within the Aparavi Platform to give you complete control on the organization of your data.
As you start to organize data with tags you will realize tags can be used many places within the platform. You can use tags as part of the query building when finding files or running reports. These reports can then be given to the appropriate people to then act on the data, whether cleaning up, removing, or even archiving the data.
You may have looked over the Custom Tagging help center documentation on how to create tags, but this will go further into concepts that can help create meaningful tags. A recurring theme amongst the use cases is going to be ROT Data (Redundant Obsolete and Trivial) and dark data. Use these as a blueprint to help build out your own tags and what makes sense for your data as you are now starting to unlock it. It is important to keep in mind there is not a right way or wrong way to make tags if it makes sense for your organization.
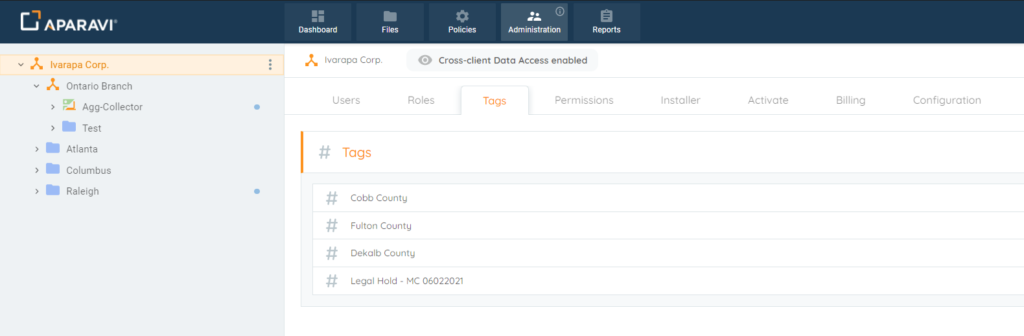
Overview
- Merger and Acquisitions
- Geographic Location
- Department
- Data Type
- Archiving Data
Merger and Acquisitions (M&A)
A powerful use of the Aparavi Platform is to function as a tool leveraging an M&A to help sort through data of the acquired organization before it is potentially brought in one central location. This could be a corporate organization that has acquired a company or even a university moving to a centralized IT department. If there is an ability to save on storage consumption before bringing the new data or find risky files, why not do it? Get rid of ROT and dark data by using Tags. Examples of Tags that could be created could be:
- Delete – Old: For anything that has not been accessed for x amount of time. Have a conversation of a timeframe in which it would be good to delete the data by all parties involved with the process.
- Delete – Redundant: Leveraging the File search or Reports find duplicate data. No need to copy over multiple copies, so have users clean up their directories to help with purging the duplicate files.
- Delete – Junk: How much data is junk sitting in the shares. Do their users store photos, music, and videos that do not pertain to the organization’s purpose? If it is not going to provide a benefit, tag it to be deleted as junk.
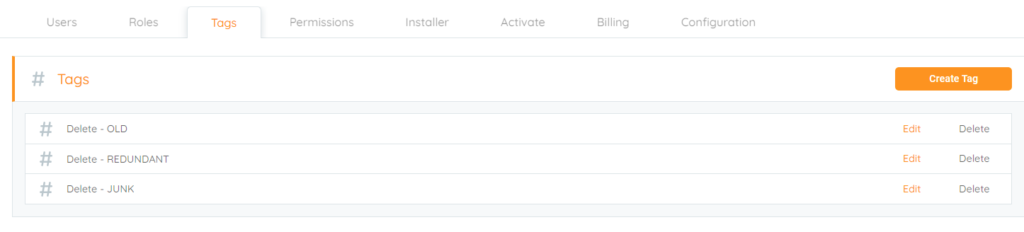
Organizations may have better names for their tags and what might make sense for them, so keep that in mind that the examples above could be named differently. The good thing is these few examples could be leveraged in other use cases as well, not just mergers and acquisitions, such as your data in general for ROT and dark data to help reclaim space.
Geographic Location
There are many organizations that have multiple locations, whether they are within a few 100 miles, across a country or global there is probably a need for an easy way to report on that data. This is even more common as the year 2020 has increased the number of users working from home and not in a certain location. Let us take some example geographic examples to base tags on:
- Global: This tag can be used on data that is used for data that could be accessed by anyone globally.
- “Country”: For users or offices that reside in the same country accessing the same file, especially if language is specific to their location and country specific compliance regulations are in place, think GDPR in the EU and how that can affect where data lives.
- “State/Region”: This is for data that can be used in a smaller geographic region. This could be data that only makes sense for the smaller region. Very similar with the country tags and GDPR, many states in the US have started to have their own Privacy acts coming into play.
- Office: Use a tag for a specific set of users that are part of a particular office or department.
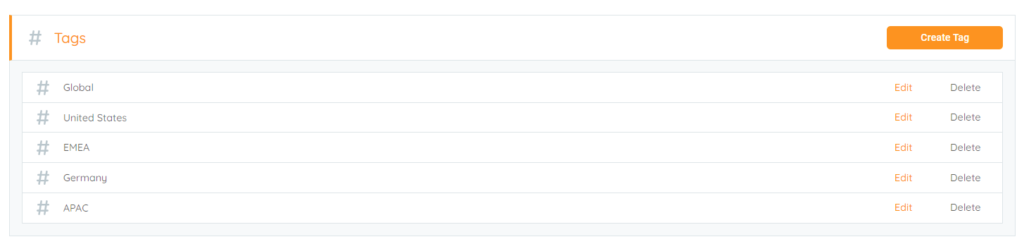
Using tags based on locations will help understand where the users are located using the data. This will also help silo that data for those users especially if the data itself does not need to be accessed by other users helping with finding file security issues. Now allows for intelligent decision on securing the shares and who has access to them based on geography/location.
Department
If you look at your organization and how you have organized file shares more than likely they are by department, but what about user shares? Sometimes those user shares are part of their respected department, or in a lot of cases a separate share just for users to store data but they are still part of a department and there are users that work with multiple departments.
Tags based on departments can help with a few different tagging scenarios, but they these can overlap with other aspects for tagging within the Aparavi Platform.
- User data- Tagging a user’s data with their assigned department makes sure the data can be moved or cleaned up based on actions against Data ROT. For example, say a user leaves the organization, then what happens to their files. Well certain files can be distinguished as files that would benefit the activity of their respected department, but there also may be files like photos, audio, videos, etc. that are trivial and have no use. Tagging the appropriate beneficial files will allow for a better decision on what can be moved to the department share and allowing deletion of the junk files.
- Using Multiple Tags- This is a great example where sales and marketing departments have input and share lots of documentation. With the ability to have multiple tags on a file it can easily distinguish those files used by multiple departments and overlap. In scenarios of data ROT and wanting to cleanup older files, you have the insight to now ask the appropriate teams if that would be suitable.
These are a couple examples on leveraging departmental tags. Users being able to distinguish their files for their respected department and the leveraging of multiple tags for multi-team documents.
Data Type
If you think about the files located on your shares, what are they? There are too many types to probably keep track of it all. There are data types that are going to be more important to your organization than others, but if we look at the last example, specific types of data can also be broken down by department. On the Aparavi Platform dashboard you can find the Files by Type widget to help get started, then maybe a custom classification to help find the data and what they are related to.
Here are some examples of data types that could make use of tags, and of course data ROT and dark data is always a consideration.
- Video Files – With these being large files of course they can be some of the first targets of data ROT, but it really comes down to who is using them. As an example, if you were to take two departments Accounting and Marketing, by theory Marketing should have a lot more video files than accounting. However, if Accounting does have a lot of videos, it may raise some questions for more digging and potential finding of trivial data that does not benefit the accounting department. This is a great example of a video tag in combination with a departmental tag to help make aware of the type of data a department uses.
- Image Files – Very similar to videos images can take up larger amount of space, such as marketing with the number of high-quality photos that are being used for all sorts of materials. However, what about user shares and the number of photos there? Granted some of that might be useful to the organization, but what if a user is backing up their personal photos to company storage. Being able to use combination of tags can help tag ROT data to clean user share consumption.
- Backup Files – Depending on your backup software or applications that have native backups there may be files that can be associated with them. A lot of times these are quite large due to the fact they are backing up full servers or large datasets, and these sometimes ten to be forgotten. Get them tagged as backup files and talk with the appropriate teams to see if they could be deleted or archived due to age.
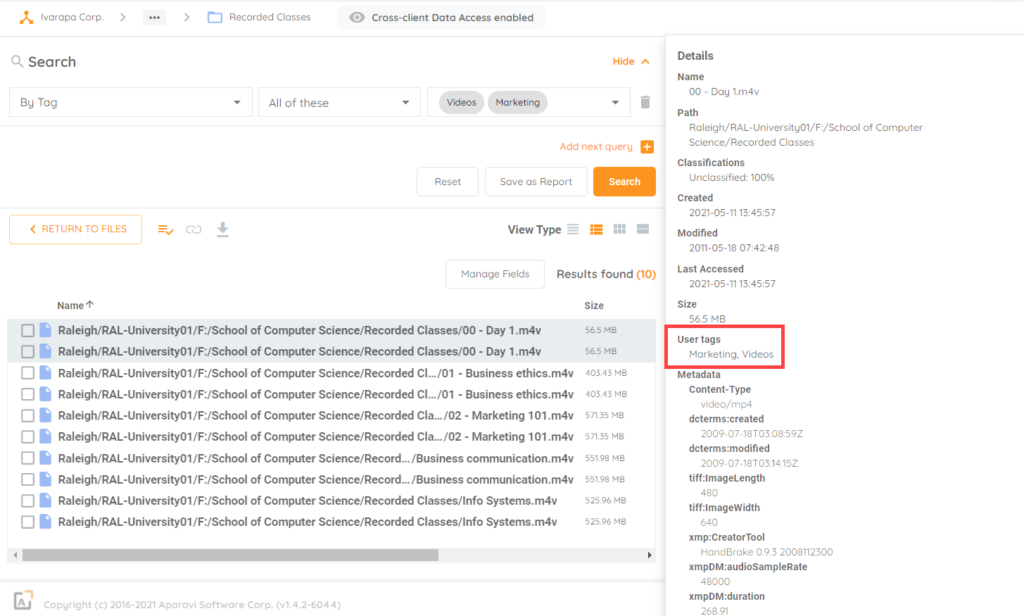
Videos, images, and backups are two great examples of the types of files that can be consuming storage that is trivial to the organization. Whether it is personal user files or trivial/obsolete data for a department, or long forgotten backups, tagging helps keep organized in knowing the data and who is using it. Giving you the facts to help clean up and gain back costly storage space.
Archiving
To finish off examples and concepts for use of tags lets talk about archiving. As you have started scanning your data you can see there might be quite a bit of data that is still required to be kept but might become ROT. There are policies in place where data must be kept for ‘x’ amount of time even though these files have not been accessed in quite some time. This data is taking up space on production storage, so moving data to cheaper storage for archive might make sense. Conceptually a couple tag example looks like this:
Archive Local – This would be a good example of where data still should remain local to an on-premises data center of the organization. This means cloud is not an option for archiving or even using a hosted datacenter. There are plenty of options for on-prem storage devices that are cost effective compared to all-flash storage arrays as an example. Based on file search queries for the data you wish to archive, leverage this tag for old data that still needs to stay local. This will help provide a faster way to know all data that can be archived but should stay local for your organization.
Archive Cloud – Cloud is another option that is growing in popularity for reason of being cost effective, but also many organizations have a cloud first mentality as they are trying to shrink on-premises datacenter footprint. If there are no restrictions to where old data that needs to be archived can live, a cloud associated tag could be used. This could even leverage specific clouds as many organizations are looking to multi-cloud strategies.
Archive Tape – Tape is still a technology used for archiving data. This would be used for data that needs to be archived that does not need to readily available, as time to retrieve data could impact business needs. Tape is great option for data that needs to be kept but not accessed.
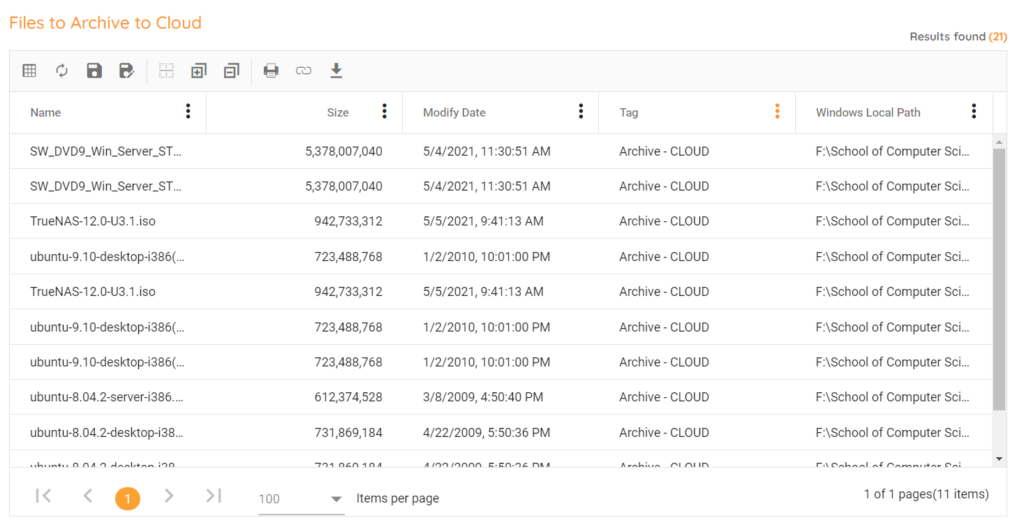
Local, Cloud and tape are three ways many organizations tend to archive data. Building archive tags within the Aparavi Portal will help organize data that needs to be archived into the proper silo destination. Using reports based on the tags will a give quick view on the data location so it then can be moved by the appropriate tool.
Conclusion
As you can see there are many things to think about when wanting to leverage tags in organizing your data beyond just its folder structure. Whether it be by location, department, or data to be marked as ROT there will be a benefit to assigning one or more tags. Take a look at create tags by running reports to help find the tagged data, then leveraging those results into making smart decisions on what might need to happen with that data.